1 概念
分组密码的模式主要是指对每一个分组明文(密文)进行迭代加(解)密的过程。主要的分组模式有以下几种:
- ECB 电子密码本(Electronic CodeBook mode)
- CBC 密码块链接(Cipher Block Chaining mode)
- CFB 密文反馈(Cipher FeedBack mode)
- OFB 输出反馈(Output FeedBack mode)
- CTR 计数器模式(CounTeR mode)
2 ECB
ECB模式中,明文分组加密后的结果直接记为密文分组,依次按顺序连接这些密文分组就是最终的密文。
ECB 加密过程:
 ECB 解密过程:
ECB 解密过程:
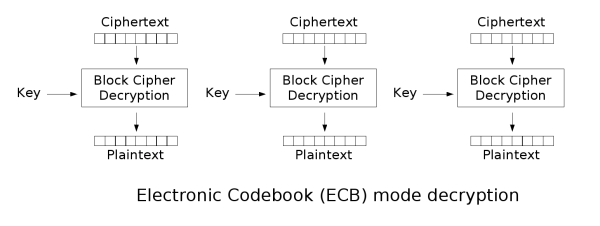
ECB是所有模式中最简单的一种模式,明文分组和密文分组是一一对应的关系,因此如果明文中存在多个相同的分组,那么他们就会被加密成相同的密文分组。在密文中通过观察这一重复性特点,就能知道明文中存在重复的组合,从而增大了被破译的风险。
再有,由于各个明文分组是独立加密的,所以如果我们将加密后的密文分组的顺序打乱,组成一个新的密文,解密者同样可以根据秘钥来解密每一个分组,但是呈现在解密者面前的信息却已经被改变。也就是说,在已知分组大小的前提下,攻击者可以不用破译密码,而通过操纵密文分组(颠倒顺序,覆盖分组等),来达到攻击的效果。
所以,ECB并不是一个安全的分组模式。
3 CBC
3.1 CBC的流程
在CBC加密流程中,首先将当前明文分组与上一密文分组(初始向量)异或,再对该值进行加密得到当前组的密文。
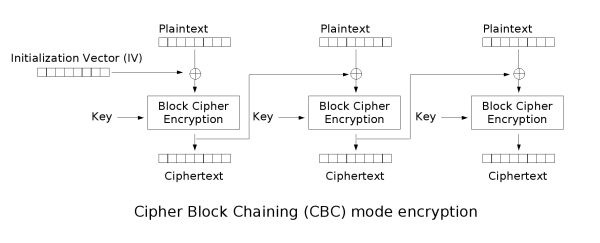
在CBC解密流程中,首先对当前密文执行解密函数,然后与上一密文分组(初始向量)异或,得到当前明文分组。
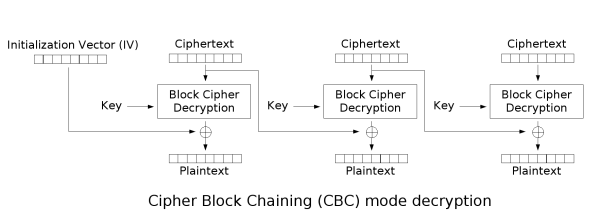
与ECB模式相比,在进行加密之前,CBC多了一步与上一密文分组(初始向量)异或的操作。
3.2 CBC的特点
- 由于加密之前会与上一密文分组(初始向量)进行异或,即便两个明文分组相同,得到的密文分组也不同。
- 分组的加密必须按顺序依次执行,无法并行
- 如果某一密文分组损坏(密文分组长度不变),在解密时,只会影响到当前和下一密文分组的解密,其他分组不受影响
- 如果某一密文分组长度被破坏,则该分组以及之后的所有分组都无法解密
- 需要填充
3.3 CBC Go的实现
// Copyright 2009 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
// Cipher block chaining (CBC) mode.
// CBC provides confidentiality by xoring (chaining) each plaintext block
// with the previous ciphertext block before applying the block cipher.
// See NIST SP 800-38A, pp 10-11
package cipher
// [Min] 分组密码之CBC模式,模式用来明确各个分组的迭代方式
// [Min] 更像是在Block外部套一层迭代方式,以及用于驱动这个迭代方式的初始向量
type cbc struct {
b Block // [Min] 承载了具体的对单一分组的加解密函数,以及秘钥
blockSize int // [Min] 分组大小
iv []byte // [Min] 初始向量
tmp []byte // [Min] 临时存储空间,长度为blockSize
}
// [Min] 根据初始向量和确定的算法实例,新建cbc实例
func newCBC(b Block, iv []byte) *cbc {
return &cbc{
b: b,
blockSize: b.BlockSize(),
iv: dup(iv), // [Min] 初始化向量的副本
tmp: make([]byte, b.BlockSize()), // [Min] 与分组大小相同
}
}
// [Min] 分组密码加密
type cbcEncrypter cbc
// cbcEncAble is an interface implemented by ciphers that have a specific
// optimized implementation of CBC encryption, like crypto/aes.
// NewCBCEncrypter will check for this interface and return the specific
// BlockMode if found.
type cbcEncAble interface {
NewCBCEncrypter(iv []byte) BlockMode
}
// NewCBCEncrypter returns a BlockMode which encrypts in cipher block chaining
// mode, using the given Block. The length of iv must be the same as the
// Block's block size.
// [Min] 构造一个CBC分组加密模式,
// [Min] 如果 block 本身实现了NewCBCEncrypter接口,直接调用即可,否则调用newCBC
func NewCBCEncrypter(b Block, iv []byte) BlockMode {
if len(iv) != b.BlockSize() {
panic("cipher.NewCBCEncrypter: IV length must equal block size")
}
if cbc, ok := b.(cbcEncAble); ok {
return cbc.NewCBCEncrypter(iv)
}
return (*cbcEncrypter)(newCBC(b, iv))
}
func (x *cbcEncrypter) BlockSize() int { return x.blockSize }
// [Min] 迭代分组,此处明文数据已经经过填充,大小恰好为分组大小的整数倍
func (x *cbcEncrypter) CryptBlocks(dst, src []byte) {
// [Min] 明文数据的大小必须是分组大小的整数倍
if len(src)%x.blockSize != 0 {
panic("crypto/cipher: input not full blocks")
}
// [Min] 输出容量必须比明文长
if len(dst) < len(src) {
panic("crypto/cipher: output smaller than input")
}
iv := x.iv
// [Min] 循环处理每一组明文
for len(src) > 0 {
// Write the xor to dst, then encrypt in place.
// [Min] 首先异或前一组密文(初始向量)和分组明文
xorBytes(dst[:x.blockSize], src[:x.blockSize], iv)
// [Min] 调用Block的Encrypt方法对该组明文进行加密
x.b.Encrypt(dst[:x.blockSize], dst[:x.blockSize])
// Move to the next block with this block as the next iv.
// [Min] 将该组密文作为下一组明文的异或对象
iv = dst[:x.blockSize]
// [Min] 调整下一组明文,密文位置
src = src[x.blockSize:]
dst = dst[x.blockSize:]
}
// Save the iv for the next CryptBlocks call.
// [Min] 保存当前最后一组密文作为下一次调用的初始向量
copy(x.iv, iv)
}
// [Min] 设置初始向量
func (x *cbcEncrypter) SetIV(iv []byte) {
if len(iv) != len(x.iv) {
panic("cipher: incorrect length IV")
}
copy(x.iv, iv)
}
// [Min] 分组密码解密
type cbcDecrypter cbc
// cbcDecAble is an interface implemented by ciphers that have a specific
// optimized implementation of CBC decryption, like crypto/aes.
// NewCBCDecrypter will check for this interface and return the specific
// BlockMode if found.
type cbcDecAble interface {
NewCBCDecrypter(iv []byte) BlockMode
}
// NewCBCDecrypter returns a BlockMode which decrypts in cipher block chaining
// mode, using the given Block. The length of iv must be the same as the
// Block's block size and must match the iv used to encrypt the data.
func NewCBCDecrypter(b Block, iv []byte) BlockMode {
if len(iv) != b.BlockSize() {
panic("cipher.NewCBCDecrypter: IV length must equal block size")
}
if cbc, ok := b.(cbcDecAble); ok {
return cbc.NewCBCDecrypter(iv)
}
return (*cbcDecrypter)(newCBC(b, iv))
}
func (x *cbcDecrypter) BlockSize() int { return x.blockSize }
func (x *cbcDecrypter) CryptBlocks(dst, src []byte) {
if len(src)%x.blockSize != 0 {
panic("crypto/cipher: input not full blocks")
}
if len(dst) < len(src) {
panic("crypto/cipher: output smaller than input")
}
if len(src) == 0 {
return
}
// [Min] 从最后一个分组开始处理,先解密,再异或前一组密文,得到该组的明文
// For each block, we need to xor the decrypted data with the previous block's ciphertext (the iv).
// To avoid making a copy each time, we loop over the blocks BACKWARDS.
end := len(src)
start := end - x.blockSize
prev := start - x.blockSize
// Copy the last block of ciphertext in preparation as the new iv.
// [Min] 保持最后一组密文作为最后返回时的初始向量
copy(x.tmp, src[start:end])
// Loop over all but the first block.
// [Min] 从后往前循环处理每一个分组
for start > 0 {
// [Min] 先解密当前分组的密文
x.b.Decrypt(dst[start:end], src[start:end])
// [Min] 再与前一分组的密文异或得到明文
xorBytes(dst[start:end], dst[start:end], src[prev:start])
// [Min] 调整前一个分组的位置
end = start
start = prev
prev -= x.blockSize
}
// The first block is special because it uses the saved iv.
// [Min] 解密第一分组
x.b.Decrypt(dst[start:end], src[start:end])
// [Min] 对于第一个分组,没有了前一个分组的密文,其异或的向量为初始向量
xorBytes(dst[start:end], dst[start:end], x.iv)
// Set the new iv to the first block we copied earlier.
// [Min] 设置初始向量为最后一个分组的密文
x.iv, x.tmp = x.tmp, x.iv
}
// [Min] 设置初始向量
func (x *cbcDecrypter) SetIV(iv []byte) {
if len(iv) != len(x.iv) {
panic("cipher: incorrect length IV")
}
copy(x.iv, iv)
}
4 CFB
4.1 CFB的流程
在CFB模式中,前一个密文分组(初始向量)会被送到密码算法的输入端,这就是密文反馈这个名字的由来。
CFB加密流程:
 CFB解密流程:
CFB解密流程:

需要注意的是,对于CFB来说,最终的密文分组是由明文分组直接和密码算法输出X异或得到的,由异或的特性可知,只需要对该密文分组再次异或相同的X即可得到对应的明文分组。换句话说,对于解密来说,我们使用的函数和加密时使用的函数是同一个函数,没有加解密之分。这一点和CBC不同。
4.2 CFB的特点
- 在ECB,CBC中,明文分组都是通过密码算法进行加密的,而CFB中,明文分组并没有直接用密码算法进行加密,密码算法只是用来对上一密文分组(初始向量)进行加密,获得一个mask,用来对该组的明密文进行加解密。
- 明文和密文之间没有加密步骤,只有异或步骤
- CFB中由密码算法输出的比特流称为密钥流,它直接影响到该分组的加解密
- 在CFB解密过程中,所有密文分组是已知的,所以每一个分组对应的密钥流就可以通过密码算法预先确定。换句话说,解密过程可以并行处理,而加密只能按分组顺序执行。
- CFB不能抵御重放攻击。如果从某一密文分组开始,被另一组相同数量的密文分组所替代,那么只有被替换的头一个分组无法解密,后续分组不受影响。这一特性,使得重放攻击成为可能。
- 不需要填充
4.3 CFB Go的实现
// Copyright 2010 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
// CFB (Cipher Feedback) Mode.
package cipher
/* [Min]
1. 对CFB来说,我们要做的核心工作是为每个分组生成密钥流,再使用这个密钥流来加解密该分组
2. 对于加,解密,生成密钥流的方法都是一样的,可以看成是对某一数据的加密,
而这个某一数据就是前一分组的密文(初始向量)
3. 加密时,先利用加密算法对前一分组的密文进行加密,得到秘钥流,再和该分组明文异或得到该组的密文
4. 解密时,先利用加密算法对前一分组的密文进行加密,得到秘钥流,再和该分组密文异或得到该组的明文
*/
// [Min] 分组密码之CFB模式
type cfb struct {
b Block // [Min] 用来对密文(初始向量)加密生成下一分组的秘钥流
next []byte // [Min] 存储当前分组的密文(初始向量)
out []byte // [Min] 存储对当前分组密文加密后的密钥流
outUsed int
decrypt bool
}
// [Min] 循环处理每一个分组,加解密都是从第一个分组开始
func (x *cfb) XORKeyStream(dst, src []byte) {
for len(src) > 0 {
// [Min] 处理第一个分组的时候,next中为初始向量,
// [Min] 后续分组 next 中为前一分组的密文,用于生成密钥流到out中
// [Min] x.outUsed == len(x.out),说明上轮循环成功加密或解密了一个分组的数据,
// [Min] 需要为后续分组创建密钥流
if x.outUsed == len(x.out) {
// [Min] 加解密调用的都是Encrypt,用来生成密钥流
x.b.Encrypt(x.out, x.next)
x.outUsed = 0
}
// [Min] 如果是解密,则从src中取出该分组密文存入next中
// [Min] 理论上,如果是解密的话,可以像OFB模式一样一次计算出多个密钥流,
// [Min] 但是这里并没有实现,next的长度还是blockSize
if x.decrypt {
// We can precompute a larger segment of the
// keystream on decryption. This will allow
// larger batches for xor, and we should be
// able to match CTR/OFB performance.
copy(x.next[x.outUsed:], src)
}
// [Min] 将当前分组和密钥流异或,得到当前分组的密文
n := xorBytes(dst, src, x.out[x.outUsed:])
// [Min] 如果是加密,则从dst中将该分组密文存入next中
if !x.decrypt {
copy(x.next[x.outUsed:], dst)
}
// [Min] 设置下一分组位置
dst = dst[n:]
src = src[n:]
x.outUsed += n
}
}
// NewCFBEncrypter returns a Stream which encrypts with cipher feedback mode,
// using the given Block. The iv must be the same length as the Block's block
// size.
func NewCFBEncrypter(block Block, iv []byte) Stream {
return newCFB(block, iv, false)
}
// NewCFBDecrypter returns a Stream which decrypts with cipher feedback mode,
// using the given Block. The iv must be the same length as the Block's block
// size.
func NewCFBDecrypter(block Block, iv []byte) Stream {
return newCFB(block, iv, true)
}
// [Min] 新建CFB秘钥流模式
func newCFB(block Block, iv []byte, decrypt bool) Stream {
blockSize := block.BlockSize()
if len(iv) != blockSize {
// stack trace will indicate whether it was de or encryption
panic("cipher.newCFB: IV length must equal block size")
}
x := &cfb{
b: block,
out: make([]byte, blockSize),
next: make([]byte, blockSize),
outUsed: blockSize,
decrypt: decrypt,
}
copy(x.next, iv)
return x
}
5 OFB
5.1 OFB的流程
OFB模式中,密码算法的输出(某一分组的密钥流)会反馈到密码算法的输入中。和CFB一样,密码算法不直接对明密文进行计算,只是用来生成分组的密钥流。
OFB加密流程:
 OFB解密流程:
OFB解密流程:

OFB模式和CFB模式极其相似,分组的加解密都是依赖于该分组的密钥流。只是生成密钥流的输入来源不同,OFB是上一组的密钥流,CFB是上一密文分组。
5.2 OFB的特点
- 与CFB类似,OFB模式的关键是分组对应的密钥流
- OFB分组秘钥流与初始化向量和分组的序号有关,各个分组的密钥流可以提前生成,这也就意味着OFB模式的分组加解密可以并行,CFB只有解密可以并行
- 如果对于某一个密钥流加密后还是该密钥流,那么该分组后续所有分组的秘钥流都相同,这可能是OFB的一个弱点
- 不需要填充
5.3 OFB Go的实现
// Copyright 2011 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
// OFB (Output Feedback) Mode.
package cipher
/* [Min]
1. 对OFB来说,与CFB类似,我们要做的核心工作是为每个分组生成密钥流,再使用这个密钥流来加解密该分组
2. 对于加,解密,生成密钥流的方法都是一样的,可以看成是对某一数据的加密,
而这个某一数据就是前一分组的密钥流(初始向量),
即对初始向量不断加密,如果加密函数为f的话,那么第i组的密钥流就是f...(f(f(iv))),i=1,2,3...
3. 与CFB略有不同的是,密钥流可以提前计算好,因为每一组对应的秘钥流只与组的索引有关,
所以我们可以提前按顺序计算好若干个组的密钥流,然后一次性对这若干个组进行加解密,提高效率
4. 如果在完成这若干个秘钥流的加解密后,还有数据,继续3中的操作,直到完成所有数据的加解密
*/
// [Min] 分组密码之OFB模式
type ofb struct {
b Block // [Min] 用来对本组密钥流(初始向量)加密生成下一分组的秘钥流
cipher []byte // [Min] 前一组密钥流(初始向量)
out []byte // [Min] 一系列按顺序通过refill计算好的密钥流
outUsed int // [Min] out中已经使用过的密钥流的总长度
}
// NewOFB returns a Stream that encrypts or decrypts using the block cipher b
// in output feedback mode. The initialization vector iv's length must be equal
// to b's block size.
// [Min] 新建OFB密钥流模式
func NewOFB(b Block, iv []byte) Stream {
blockSize := b.BlockSize()
if len(iv) != blockSize {
panic("cipher.NewOFB: IV length must equal block size")
}
// [Min] out的容量最低取512字节,如果blockSize超过512,按blockSize计算
bufSize := streamBufferSize
if bufSize < blockSize {
bufSize = blockSize
}
x := &ofb{
b: b,
cipher: make([]byte, blockSize),
out: make([]byte, 0, bufSize),
outUsed: 0,
}
copy(x.cipher, iv)
return x
}
// [Min] 根据outUsed,移去out中已使用过的密钥流,并计算后续密钥流
func (x *ofb) refill() {
bs := x.b.BlockSize()
remain := len(x.out) - x.outUsed
// [Min] 如果剩余的大于已使用的,说明剩余的至少还有一个完整的密钥流未使用,直接返回
if remain > x.outUsed {
return
}
// [Min] 从out中移去已使用的密钥流
copy(x.out, x.out[x.outUsed:])
// [Min] 保留remain的部分,并初始化后续数据
x.out = x.out[:cap(x.out)]
// [Min] 累计计算密钥流,并添加到remain中,直到无法再次添加一个完整的密钥流为止
for remain < len(x.out)-bs {
x.b.Encrypt(x.cipher, x.cipher)
copy(x.out[remain:], x.cipher)
remain += bs
}
// [Min] 保留当前所有未使用的秘钥流,置outUsed为0
x.out = x.out[:remain]
x.outUsed = 0
}
// [Min] 通过out中的密钥流,对明文,密文加解密
func (x *ofb) XORKeyStream(dst, src []byte) {
for len(src) > 0 {
// [Min] 如果out中剩余未使用的部分不够一个密钥流的长度,
// [Min] 则需要从out中移去已使用过的密钥流,并且计算后续的密钥流
if x.outUsed >= len(x.out)-x.b.BlockSize() {
x.refill()
}
// [Min] 一次性从src中加解密与out中未使用的秘钥流对应的相同数量的明文或密文
n := xorBytes(dst, src, x.out[x.outUsed:])
// [Min] 设置下一次加解密的起点位置
dst = dst[n:]
src = src[n:]
x.outUsed += n
}
}
6 CTR
6.1 CTR的流程
与OFB相似,CTR模式是一种通过将逐次累加的计数器进行加密来生成密钥流的流密码。每一个分组对应一个逐次累加的计数,该计数用于生成该分组的秘钥流。
CTR加密流程:
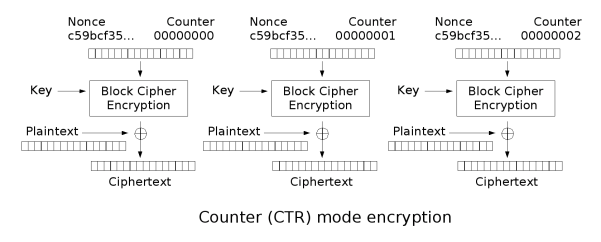 CTR解密流程:
CTR解密流程:
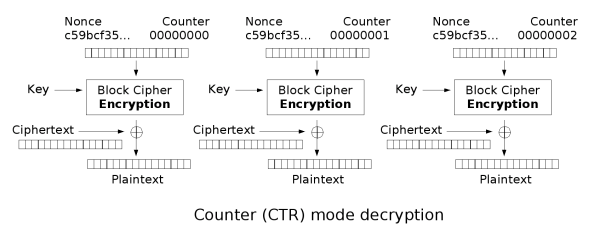
计数器一般由一个随机数nonce确定,nonce + 一定位数的计数空间构成了该计数器。
6.2 CTR的特点
- 和OFB类似,CTR也是利用秘钥流进行加解密
- 生成CTR秘钥流的来源是该分组的计数
- CTR加解密可以并行
- 由于密码算法的输入是各组对应的不同的计数,分组的秘钥流就不同,因此CTR没有OFB中提到的弱点
- 不需要填充
6.3 CTR Go的实现
// Copyright 2009 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
// Counter (CTR) mode.
// CTR converts a block cipher into a stream cipher by
// repeatedly encrypting an incrementing counter and
// xoring the resulting stream of data with the input.
// See NIST SP 800-38A, pp 13-15
package cipher
/* [Min]
1. 对CTR来说,与OFB极其类似,我们要做的核心工作也是为每个分组生成密钥流,再使用这个密钥流来加解密该分组
2. 对于加,解密,生成密钥流的方法都是一样的,可以看成是对某一数据的加密,
而这个某一数据就是当前分组的计数值,
如果加密函数为f的话,初始计数为A,那么第i组的密钥流就是f(A+i-1),i=1,2,3...
3. 同样,密钥流也可以提前计算好,因为每一组对应的秘钥流只与组的索引有关,(初始计数已确定)
所以我们可以提前按顺序计算好若干个组的密钥流,然后一次性对这若干个组进行加解密,提高效率
4. 如果在完成这若干个秘钥流的加解密后,还有数据,继续3中的操作,直到完成所有数据的加解密
*/
// [Min] 分组密码之CTR模式
type ctr struct {
b Block // [Min] 用来对本组计数加密生成下一分组的秘钥流
ctr []byte // [Min] 分组计数器,长度与blockSize相同,可以把byte切片看成一个连起来的大数
out []byte // [Min] 一系列密钥流
outUsed int // [Min] out中已使用的密钥流
}
const streamBufferSize = 512
// ctrAble is an interface implemented by ciphers that have a specific optimized
// implementation of CTR, like crypto/aes. NewCTR will check for this interface
// and return the specific Stream if found.
type ctrAble interface {
NewCTR(iv []byte) Stream
}
// NewCTR returns a Stream which encrypts/decrypts using the given Block in
// counter mode. The length of iv must be the same as the Block's block size.
func NewCTR(block Block, iv []byte) Stream {
if ctr, ok := block.(ctrAble); ok {
return ctr.NewCTR(iv)
}
if len(iv) != block.BlockSize() {
panic("cipher.NewCTR: IV length must equal block size")
}
bufSize := streamBufferSize
if bufSize < block.BlockSize() {
bufSize = block.BlockSize()
}
return &ctr{
b: block,
ctr: dup(iv),
out: make([]byte, 0, bufSize),
outUsed: 0,
}
}
// [Min] 尽可能多地在out中计算密钥流
func (x *ctr) refill() {
remain := len(x.out) - x.outUsed
copy(x.out, x.out[x.outUsed:])
x.out = x.out[:cap(x.out)]
bs := x.b.BlockSize()
for remain <= len(x.out)-bs {
x.b.Encrypt(x.out[remain:], x.ctr)
remain += bs
// Increment counter
// [Min] 从最后一个字节开始尝试加1,如果没有溢出,跳出循环
// [Min] 否则高一个字节进一位
for i := len(x.ctr) - 1; i >= 0; i-- {
x.ctr[i]++
if x.ctr[i] != 0 {
break
}
}
}
x.out = x.out[:remain]
x.outUsed = 0
}
// [Min] 与OFB类似
func (x *ctr) XORKeyStream(dst, src []byte) {
for len(src) > 0 {
if x.outUsed >= len(x.out)-x.b.BlockSize() {
x.refill()
}
n := xorBytes(dst, src, x.out[x.outUsed:])
dst = dst[n:]
src = src[n:]
x.outUsed += n
}
}